





Quand un NAS affiche une alerte de disque défaillant, la première réaction est souvent de vouloir réparer au plus vite. C’est compréhensible, mais c’est aussi le moment où les erreurs les plus coûteuses sont commises. Entre la réinitialisation qui efface les métadonnées RAID, la reconstruction lancée sans vérifier l’état des disques restants, et le contrôle de fichiers qui aggrave la corruption, chaque mauvaise décision réduit les chances de récupération. La panne initiale n’est pas toujours le véritable problème ; c’est la réponse à la panne qui souvent va déterminer si les données seront récupérables ou non. Si votre NAS Synology ou QNAP est en panne, notre laboratoire réalise un diagnostic gratuit de votre serveur ou NAS et intervient sur toutes les configurations.
Ce qui se passe quand un NAS tombe en panne
Un NAS Synology ou QNAP repose sur une grappe RAID logicielle gérée par le système d’exploitation du boîtier (DSM chez Synology, QTS ou QuTS hero chez QNAP). Lorsqu’un disque tombe en panne, le NAS passe en mode dégradé : il continue de fonctionner en recalculant les données manquantes à la volée grâce à la parité (en SHR, RAID 5 ou RAID 6) ou à la copie miroir (en RAID 1 ou RAID 10). Le volume reste accessible, mais toute la charge repose désormais sur les disques survivants.
C’est précisément dans cette fenêtre de vulnérabilité que la majorité des pertes de données définitives se produisent. Non pas à cause de la panne initiale, mais à cause des possibles manipulations effectuées dans la précipitation par l’utilisateur ou l’administrateur. Notre laboratoire traite régulièrement des NAS dont les données auraient été récupérables si aucune action n’avait été entreprise après la panne.
Les erreurs qui transforment une panne récupérable en perte définitive
Relancer une reconstruction sans sauvegarde préalable
La première chose que propose l’interface DSM ou QTS lorsqu’un disque est déclaré défaillant, c’est de remplacer le disque et de reconstruire le pool de stockage. L’opération semble simple : on insère un disque neuf, on clique sur « Réparer », et le NAS reconstruit la grappe. En pratique, cette reconstruction soumet chaque disque survivant à une lecture intégrale de tous ses secteurs, pendant plusieurs heures à plusieurs jours selon la capacité. Si un second disque présente des secteurs défectueux ou des signes de fatigue, il peut tomber en panne pendant la reconstruction et faire basculer le volume de l’état « dégradé » vers l’état « crashé », c’est-à-dire inaccessible.
Ce scénario n’est pas théorique. Sur les forums Synology et QNAP, les témoignages d’utilisateurs ayant perdu l’intégralité de leur volume pendant une reconstruction sont nombreux. Le réflexe correct est de sauvegarder toutes les données accessibles avant de lancer la moindre reconstruction, même si le volume est encore lisible en mode dégradé. C’est contre-intuitif, parce que l’interface invite à réparer immédiatement, mais c’est la seule façon de se prémunir contre une défaillance en chaîne.
Réinitialiser le NAS ou recréer le pool de stockage
Chez QNAP, plusieurs options de réinitialisation coexistent dans l’interface : réinitialisation logicielle (soft reset), restauration des paramètres d’usine, et réinitialisation complète avec reformatage des volumes. La confusion entre ces options est fréquente, et les conséquences sont très différentes. Un soft reset conserve les données. Un reformatage les détruit. Lorsque le NAS ne démarre plus correctement ou affiche un comportement anormal après une panne disque, le premier réflexe de beaucoup d’administrateurs est de tenter une réinitialisation. Si l’option choisie inclut le reformatage du pool, toutes les données sont écrasées.
Chez Synology, le risque équivalent survient lorsqu’un utilisateur supprime un pool de stockage « crashé » puis en recrée un nouveau sur les mêmes disques, en pensant que l’opération va « réparer » le volume. En réalité, la création d’un nouveau pool écrase les métadonnées RAID (le superbloc mdadm) qui permettent de reconstituer la grappe. Sans ces métadonnées, la récupération devient beaucoup plus complexe et coûteuse.
Retirer ou intervertir des disques sans précaution
Sur un NAS utilisant un RAID logiciel (mdadm pour Synology DSM et QNAP QTS, ZFS pour QNAP QuTS hero), l’ordre physique des disques dans les baies n’est pas critique : les métadonnées RAID stockées sur chaque disque permettent au système de reconstituer la grappe indépendamment de la position. Cependant, cette règle ne s’applique que si aucune autre opération n’a été effectuée entre-temps. Le problème survient quand un administrateur retire un disque qu’il croit défaillant alors que le disque fonctionne encore, ou quand il retire plusieurs disques simultanément pour « vérifier ». QNAP documente explicitement ce risque : si le nombre de disques retirés dépasse la tolérance du niveau RAID, le volume passe en état « Error » et les données deviennent inaccessibles.
Lorsqu’un disque est retiré d’un NAS en fonctionnement, le système le marque immédiatement comme absent dans les métadonnées de la grappe. À partir de cet instant, toute écriture sur le volume crée un écart de synchronisation entre ce disque et les autres membres. Si le disque est réinséré après que des données ont été modifiées, le NAS ne peut plus le considérer comme à jour et déclenche une déclenche une resynchronisation ( partielle si le NAS tient à jour une carte des zones modifiées, complète dans les autres cas) avec les risques que cela comporte sur des disques déjà sollicités. La réinsertion immédiate, sans aucune écriture intermédiaire, reste le seul cas où le NAS peut réintégrer un disque sans déclencher de phase de reconstruction.
Utiliser un disque de remplacement incompatible
Dans le contexte actuel de pénurie de disques durs, la tentation est forte de remplacer un disque défaillant par le premier modèle disponible. Deux erreurs reviennent régulièrement. La première est d’insérer un disque de capacité inférieure à celle des autres membres de la grappe : le NAS refusera tout simplement la reconstruction, et le volume restera en état dégradé sans possibilité de réparation tant qu’un disque de capacité égale ou supérieure n’aura pas été inséré. La seconde est d’utiliser un disque SMR (enregistrement magnétique à tuiles) à la place d’un disque CMR (enregistrement magnétique conventionnel). Les disques SMR, conçus pour maximiser la densité de stockage en superposant les pistes magnétiques, sont pénalisés en écriture aléatoire et soutenue. Lors d’une reconstruction RAID, le cache interne du disque sature rapidement et le disque suspend les opérations d’entrée/sortie le temps de réécrire les données dans les zones à pistes superposées, ce qui provoque des timeouts du contrôleur et peut entraîner l’éjection du disque en pleine reconstruction. »
La distinction CMR/SMR n’est pas toujours explicite dans la désignation commerciale des disques. Certains modèles grand public ont été commercialisés en SMR sans mention claire, ce qui a fait l’objet d’un recours collectif contre Western Digital en 2020 pour ses anciens modèles WD Red. Avant d’insérer un disque de remplacement dans un NAS, la référence exacte doit être vérifiée sur le site du fabricant pour confirmer la technologie d’enregistrement. Notre article CMR vs SMR détaille les différences entre ces deux architectures et les modèles à privilégier en environnement RAID.
Lancer un contrôle de fichiers sur un volume dégradé
Après une panne, l’interface du NAS peut suggérer un contrôle d’intégrité du système de fichiers (équivalent d’un FSCK sous Linux ou CHKDSK sous Windows). Sur un volume sain, cette opération est bénigne. Sur un volume dégradé ou partiellement corrompu, elle peut aggraver la situation : le contrôle tente de « réparer » des incohérences en supprimant ou en déplaçant des blocs, ce qui peut détruire les traces exploitables par un spécialiste de la récupération. Le système de fichiers Btrfs, utilisé par défaut sur les modèles Synology récents, est particulièrement sensible à ce type d’intervention lorsque les données sous-jacentes sont incomplètes.
Un contrôle de fichiers parcourt les structures internes du système de fichiers (tables d’allocation, journaux, répertoires) et corrige les incohérences qu’il détecte. Sur un volume dégradé, certaines données sont absentes parce qu’un disque manque. Le contrôle interprète ces absences comme des corruptions : il supprime les entrées de répertoire orphelines, tronque les fichiers dont la taille déclarée ne correspond plus à l’espace alloué, ou réécrit les arbres de métadonnées (notamment les arbres d’extents et de checksums en Btrfs). Ces modifications sont irréversibles et éliminent précisément les traces dont un spécialiste a besoin pour reconstituer les fichiers. Un contrôle de fichiers ne doit être lancé qu’après une copie complète des données, ou pas du tout.
Continuer à utiliser le NAS en mode dégradé sans agir
À l’opposé de la précipitation, l’inaction prolongée est tout aussi dangereuse. Certains utilisateurs voient l’alerte « dégradé » et décident de continuer à travailler normalement, repoussant le remplacement du disque à plus tard. Pendant ce temps, les disques restants subissent une charge accrue (ils doivent recalculer en permanence les données du disque absent), ce qui accélère leur usure. Plus le NAS fonctionne longtemps en mode dégradé, plus la probabilité d’une seconde panne augmente. Et en RAID 5 ou SHR-1, une seconde panne signifie la perte du volume.
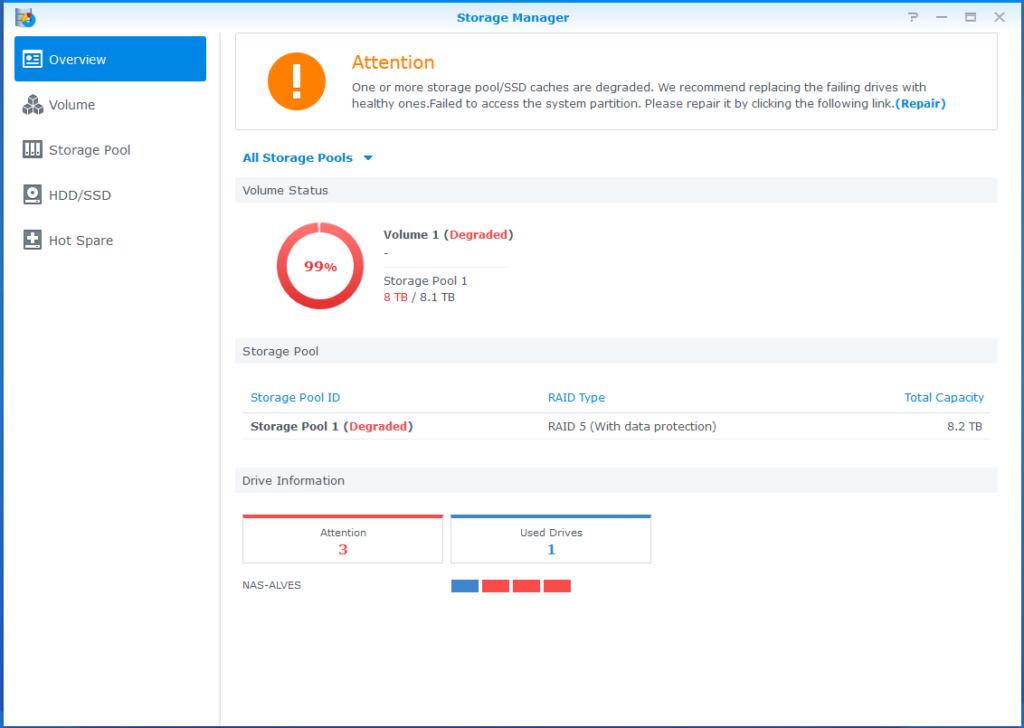
Le risque ne se limite pas à une seconde panne mécanique. En mode dégradé, chaque opération de lecture oblige le NAS à recalculer les données du disque absent à partir de la parité. Si, au cours de ce recalcul, un autre disque rencontre une erreur de lecture non récupérable (URE) (un secteur que son firmware ne parvient pas à lire correctement), le bloc de données concerné est définitivement perdu. Sur des disques de grande capacité, la probabilité de rencontrer une URE lors de la lecture de plusieurs téraoctets est statistiquement significative. Contrairement à une panne franche qui met le volume hors ligne, une URE isolée n’affecte qu’un ou quelques blocs : les fichiers touchés restent visibles dans l’arborescence mais deviennent illisibles ou corrompus, parfois sans que l’alerte remontée dans les logs soit immédiatement identifiée comme telle. Un NAS ne devrait pas fonctionner en mode dégradé plus longtemps que le temps strictement nécessaire à la mise en sécurité des données et au remplacement du disque.
Ce qu’il faut faire concrètement
Lorsqu’un NAS Synology ou QNAP signale une panne disque, la marche à suivre dépend de la criticité des données et de l’existence ou non d’une sauvegarde.
Si une sauvegarde récente et vérifiée existe, la situation est maîtrisée. On peut remplacer le disque défaillant et lancer la reconstruction via l’interface du NAS en suivant la procédure documentée par le fabricant. Même dans ce cas, il est préférable de vérifier l’état SMART des disques survivants avant de lancer le rebuild, et de réduire la charge sur le NAS pendant l’opération.
Si aucune sauvegarde exploitable n’existe, la prudence s’impose. Avant toute manipulation, il faut copier les données accessibles sur un support externe, même partiellement. Si le volume est déjà en état « crashé » et inaccessible, la meilleure décision est de ne rien faire : éteindre proprement le NAS, étiqueter chaque disque avec son numéro de baie, et contacter un laboratoire spécialisé. Toute tentative de réinitialisation, de recréation de pool ou de reconstruction sur un volume crashé risque d’écraser les métadonnées nécessaires à la récupération.
Notre laboratoire reçoit régulièrement des NAS dont les données étaient intégralement récupérables à l’origine, mais qui sont arrivés après deux ou trois tentatives de réparation ayant progressivement détruit les structures logiques. Plus le nombre de manipulations est élevé, plus la récupération est longue, complexe et incertaine.
Le cas particulier des NAS chiffrés
Les NAS Synology et QNAP proposent plusieurs mécanismes de chiffrement, dont les implications en cas de panne sont très différentes. Lorsque le chiffrement est actif, la récupération de données après une panne devient considérablement plus difficile, voire impossible si la clé de chiffrement n’est pas disponible
Sur Synology DSM, le mécanisme le plus répandu est le chiffrement des dossiers partagés. Chaque dossier chiffré possède sa propre clé, un fichier .key exportable depuis l’interface DSM. À l’activation du chiffrement, DSM propose soit de sauvegarder cette clé manuellement sous forme d’un fichier .key, soit de la confier au gestionnaire de clés intégré (Key Manager), qui la stocke sur le NAS et la monte automatiquement au démarrage. Dans ce second cas, si le boîtier tombe en panne et que la clé de récupération n’a jamais été exportée sur un support externe, il devient impossible de déchiffrer les données sur un autre système, même si les disques sont physiquement intacts. Les disques contiennent alors des données chiffrées récupérables en théorie, mais inaccessibles sans la clé de récupération que seul DSM peut normalement fournir. Les modèles récents proposent également un chiffrement au niveau du volume entier, basé sur LUKS (Linux Unified Key Setup), dont la clé de récupération suit la même logique : elle doit impérativement être sauvegardée en dehors du NAS pour permettre une récupération sur une autre machine.
Sur QNAP QTS, le chiffrement des volumes fonctionne de manière comparable, avec des clés liées aux volumes ou aux dossiers partagés. Sur QuTS hero, le chiffrement natif ZFS ajoute une couche supplémentaire avec ses propres mécanismes de gestion de clés, distincts de ceux de QTS.
La première question à se poser face à un NAS en panne est donc : le chiffrement était-il activé, et la clé existe-t-elle en dehors du NAS ? Cette information conditionne l’ensemble de la stratégie de récupération et doit être communiquée au laboratoire dès le premier contact. Pour les NAS encore en fonctionnement, la vérification est simple : ouvrir les paramètres de chiffrement, exporter les clés et les stocker dans un emplacement distinct du NAS.
Liens utiles vers les ressources officielles Synology et QNAP
Les supports de Synology et QNAP sont riches mais leur navigation n’est pas toujours intuitive. Voici les pages les plus directement utiles en cas de panne.
Synology (DSM)
- Réparer un groupe de stockage dégradé : procédure pas à pas, conditions sur la taille du disque de remplacement, réparation rapide et réparation automatique.
- Que faire quand un volume plante : les quatre scénarios (système éteint, données illisibles, données encore accessibles, disque retiré par erreur) et les actions correspondantes.
- Récupérer les données d’un NAS en panne via un PC Linux : montage mdadm, volumes chiffrés (LUKS et eCryptfs). Procédure technique détaillée, à réserver aux utilisateurs avertis.
QNAP (QTS / QuTS hero)
- Remplacer un disque défectueux dans un groupe RAID : remplacement manuel, disque de rechange automatique, cas où la reconstruction ne démarre pas.
- Disques retirés accidentellement : diagnostic selon le type de RAID, récupération en mode dégradé et en mode erreur, vérification du système de fichiers.
FAQ sur les panne de NAS Synology ou QNAP
Un état « Crashed » ne signifie pas nécessairement que les disques sont physiquement défaillants. Le problème peut venir d’une corruption des métadonnées RAID, d’une coupure de courant ou d’un bug du système d’exploitation. Ne tentez pas de recréer le pool de stockage. Éteignez le NAS, notez le numéro de baie de chaque disque et contactez un spécialiste. Dans beaucoup de cas, les données sont intactes sur les disques et la grappe peut être reconstruite virtuellement sans toucher aux supports d’origine.
Si vous réinsérez le disque dans la même baie sans avoir effectué d’autre opération entre-temps, le NAS proposera normalement une reconstruction. QNAP documente cette procédure et précise que le disque doit être remis dans son emplacement d’origine. En revanche, si d’autres manipulations ont été effectuées (retrait d’un second disque, tentative de réinitialisation, création d’un nouveau volume), les chances de récupération automatique diminuent fortement.
Oui. Si la panne concerne le boîtier (carte mère, alimentation, contrôleur réseau) et non les disques, les données sont toujours présentes sur les supports. La procédure de récupération dépend cependant de l’architecture du NAS. Sur Synology DSM et QNAP QTS, le RAID repose sur mdadm : les métadonnées sont stockées sur les disques eux-mêmes, et un laboratoire spécialisé peut reconstituer le volume indépendamment du boîtier d’origine. Synology documente même une procédure pour monter les disques sur un PC Linux, mais celle-ci requiert des compétences techniques solides et comporte des risques si elle est mal exécutée. Sur QNAP QuTS hero, l’architecture repose sur ZFS : les outils de récupération sont entièrement différents, et la reconstruction du pool nécessite une expertise ZFS spécifique. Notre laboratoire intervient sur les deux architectures et adapte sa méthode à chaque configuration.
En cas de doute, un seul réflexe
Un NAS en panne avec des données critiques et sans sauvegarde est une situation d’urgence, pas un exercice de dépannage. Chaque manipulation supplémentaire réduit les chances de récupération. Si vous n’êtes pas certain de la marche à suivre, éteignez le NAS, ne touchez à rien et contactez notre équipe. Nous réalisons un diagnostic gratuit sous 4 heures et nous clonons systématiquement chaque disque avant toute intervention, pour garantir que les données d’origine ne sont jamais altérées. Demander un diagnostic gratuit →